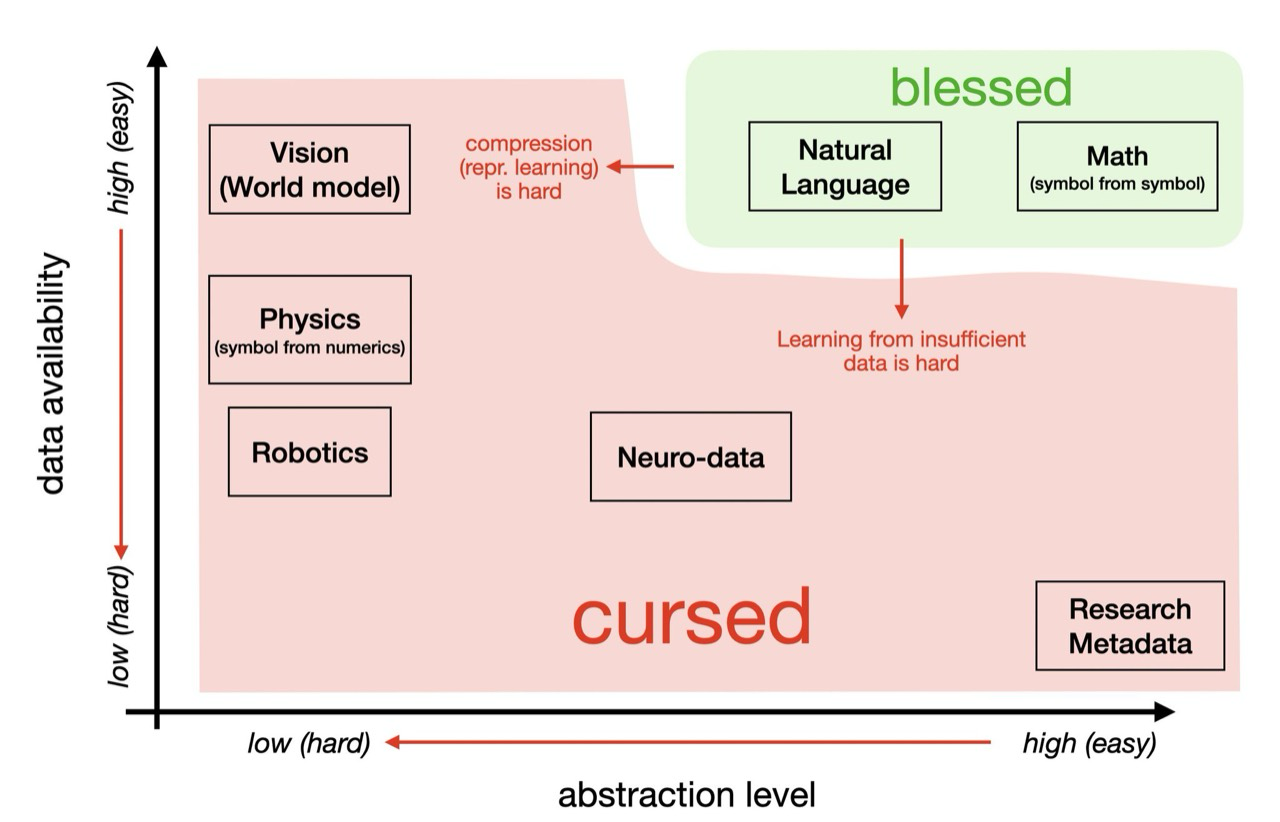
AI systems get easier when abstraction is high and data is abundant. Natural language and math have pretraining support and clean symbolic structure. They sit in the blessed region.
Physical AI, robotics, neuro-data, world models, cognitive security, and research metadata sit closer to cursed regions: lower data, weaker ground truth, harder compression, unstable objectives.
Thesis
The durable work is making messy reality legible enough to act on.
In cursed regions, the first job is not picking the biggest model. It is building an environment truthful enough that model improvement means something.
The map
High-abstraction, high-data tasks can borrow structure from pretraining.
Lower-data or lower-abstraction domains need explicit scaffolds: object identity, typed relations, state boundaries, hard validators, trace capture, and human review loops.
This is why my work keeps returning to the same pattern across unrelated domains: preserve the artifact, expose constraints, build validators, and learn only the residual.
Why blessed-region methods fail elsewhere
Benchmarks become products. Final rewards smear credit. Models appear smart because the base distribution was already fertile.
Capability jumps can make a method look causal when the model crossed a threshold where the task became compressible.
Agent systems make the issue sharper. Post-training depends on whether the environment produces localized feedback.
Tool-call failures, state-boundary violations, runtime errors, and verifier failures should become correction signals, not terminal noise spread across whole rollouts.
What survives in cursed regions
- Exact artifacts and preserved provenance.
- Stable object identity and typed relations.
- State boundaries, hard validators, and calibrated uncertainty.
- Trace capture, review loops, and operator-facing evidence.
- Learned residuals only after the measurable environment exists.
How this shows up in my work
T-UEBA used constrained graph ML, active learning, synthetic-data triggers, and calibration because tactical behavior does not stay stationary.
AIxCC / DL-Patcher used code-model harnesses, checker feedback, patch verification, and human-in-loop repair because code repair needs verifier pressure.
DXF-to-CAD treats drawings as structured artifact environments: HATCH-IoU, hard validators, typed geometry, and learned residual repair.
The Applied Medical and Drone Services Startup work had the same shape: make the workflow legible enough for action.
Practical rule
Build the environment and measurement loop first. Spend compute only where the feedback signal is real.
Research map · Agent post-training as environment design · Selected work